服务器集群的搭建与配套的数据处理和存储支持服务构成了现代企业IT基础设施的核心。一个设计良好的集群能够提供高性能、高可用性和强大的横向扩展能力,以满足多样化的业务需求。
一、 服务器集群的主流搭建技术栈
服务器集群的搭建并非依赖于单一工具,而是一个融合了硬件、操作系统、虚拟化/容器化、编排调度和网络技术的完整技术栈。
1. 硬件与基础层
- 物理服务器:通常采用标准化、高密度的机架式或刀片式服务器,品牌如戴尔PowerEdge、HPE ProLiant、浪潮等。
- 网络:高速网络是集群的神经系统。普遍采用万兆(10GbE)甚至更高速率的以太网,并常通过叶脊(Spine-Leaf)架构来保证低延迟和高带宽。InfiniBand网络则常见于高性能计算(HPC)场景。
- 存储硬件:根据需求配置直连存储(DAS)、存储区域网络(SAN)或网络附加存储(NAS)。
2. 虚拟化与操作系统
- 虚拟化:用于将物理资源池化,提升利用率。主流方案包括VMware vSphere、微软Hyper-V、开源的KVM和Xen。
- 操作系统:Linux发行版占据绝对主导地位,如CentOS/RHEL、Ubuntu Server、SUSE Linux Enterprise Server,因其稳定性、高性能和丰富的开源生态。
3. 容器化与编排平台(现代集群的核心)
- 容器运行时:Docker是创建标准化应用单元(容器)的事实标准。
- 容器编排:Kubernetes (K8s) 已成为容器编排领域的绝对王者,它自动化了容器的部署、扩展、管理和网络通信,是构建云原生集群的基石。其他方案如Docker Swarm和Apache Mesos也有特定应用。
4. 配置管理与部署
- 工具:用于自动化服务器配置和应用部署,如Ansible、Puppet、Chef、SaltStack。它们能确保集群节点配置的一致性。
二、 数据处理与存储支持服务
集群搭建后,需要在其上部署专门的服务来处理和存储海量数据。这些服务通常以分布式、可扩展的方式运行在集群之上。
1. 分布式存储服务
- 对象存储:适用于存储海量非结构化数据(如图片、视频、备份)。
- 开源:Ceph(提供统一存储接口)、MinIO(高性能,S3兼容)。
- 公有云服务:AWS S3、阿里云OSS、腾讯云COS。
- 分布式文件系统:提供像本地文件系统一样的访问方式,但具备横向扩展能力。
- HDFS:Hadoop生态的核心,为批处理优化。
- CephFS:Ceph提供的POSIX兼容文件系统。
- GlusterFS:横向扩展的网络附加存储文件系统。
- 块存储:为虚拟机或容器提供高性能、可动态挂载的块设备,如Ceph RBD、iSCSI over SAN。
2. 大数据处理框架
- 批处理:
- Apache Hadoop MapReduce:经典的大数据批处理模型。
- Apache Spark:内存计算,速度远超MapReduce,支持批处理、流处理和机器学习。
- 流处理:
- Apache Flink:高吞吐、低延迟、精确一次处理的流处理引擎。
- Apache Kafka Streams:轻量级库,用于在Kafka内部构建流处理应用。
- Apache Storm:较早的分布式实时计算系统。
3. 数据库与数据仓库
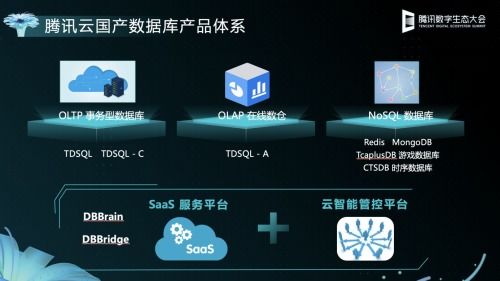
- NoSQL数据库(面向海量非关系型数据):
- 键值存储:Redis(内存型)、Apache Cassandra(宽列,高可用)。
- 文档存储:MongoDB、Couchbase。
- 时序数据库:InfluxDB、Prometheus(监控领域)。
- 分布式SQL/数据仓库:
- MPP数据库:ClickHouse(极致分析性能)、Greenplum、Apache Impala。
- 云原生数据仓库:Snowflake(SaaS模式)、Amazon Redshift、Google BigQuery。
4. 消息队列与事件流平台
- 作为集群内服务间的异步通信和数据管道中枢,实现解耦和削峰填谷。
- Apache Kafka:高吞吐分布式事件流平台,是实时数据管道的标准。
- RabbitMQ:功能丰富的开源消息代理,支持多种协议。
- Apache Pulsar:云原生分布式消息流平台,兼具高吞吐和灵活消费模型。
三、 典型技术栈组合示例
- 云原生微服务集群:
- 基础设施:裸金属服务器或云主机 + 万兆网络。
- 编排核心:Kubernetes。
- 存储:Ceph RBD(容器持久卷) + MinIO(对象存储)。
- 数据服务:MySQL/PostgreSQL(有状态应用,可通过Operator管理)+ Redis(缓存)+ Kafka(服务间通信)。
- 大数据分析集群:
- 基础设施:多节点标准服务器,大内存配置。
- 计算框架:Apache Spark on YARN 或 Kubernetes。
- 存储:HDFS 或 对象存储(如S3协议)。
- 资源调度:Apache YARN 或 Kubernetes。
- 查询引擎:Presto/Trino 或 Apache Hive。
###
构建服务器集群是一个系统性的工程。现代实践通常以Kubernetes作为容器化应用的统一编排平台,在其之上根据业务需求,灵活选择和集成各类分布式存储、数据处理框架和数据服务。硬件的选择、网络架构的设计以及配置管理的自动化,共同构成了集群稳定、高效的基石。最终技术栈的选取,需在性能、成本、复杂度及团队技术能力之间取得最佳平衡。