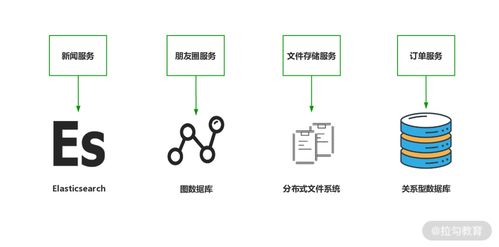
在微服务架构中,数据处理与存储的设计直接关系到系统的可扩展性、一致性和可维护性。以下是五条宝贵的经验教训,旨在帮助开发者在设计微服务时避免常见陷阱,构建高效可靠的数据层。
1. 明确数据所有权,避免共享数据库
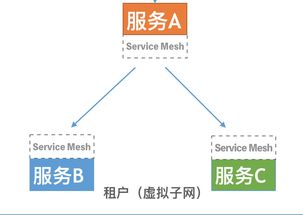
每个微服务应拥有自己的私有数据库,数据模型和存储机制应由服务自身管理。这确保了服务之间的松耦合,避免了因共享数据库导致的变更连锁反应。当服务需要其他服务的数据时,应通过定义良好的API(如REST或gRPC)进行交互,而不是直接访问对方的数据库。
2. 采用最终一致性,而非强一致性
在分布式系统中,跨服务的强一致性往往代价高昂且影响性能。优先考虑最终一致性模式,通过事件驱动架构(如使用消息队列)来异步同步数据。例如,订单服务在创建订单后发布一个“订单创建”事件,库存服务订阅该事件并异步更新库存。这提高了系统的响应速度和容错能力。
3. 为数据存储选择合适的技术
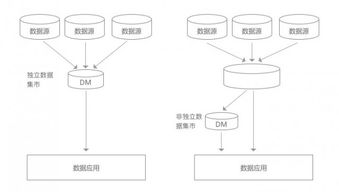
不要试图用单一数据库解决所有问题。根据服务的数据特性选择专用存储:关系型数据库(如PostgreSQL)适合事务性操作,文档数据库(如MongoDB)处理灵活模式,时序数据库(如InfluxDB)优化时间序列数据。这种多语言持久化策略能充分发挥各类数据库的优势。
4. 实施数据分片与分区策略
随着数据量增长,单一数据库实例可能成为瓶颈。设计时应提前规划数据分片(如按用户ID或地域分区),以支持水平扩展。例如,用户服务可以将不同地区的用户数据存储在不同的数据库分片中,从而分散负载并提高查询效率。
5. 确保数据安全与合规性
数据处理必须内置安全措施,包括加密敏感数据(如用户密码)、实施访问控制(基于角色的权限)和审计日志记录。在涉及多区域部署时,还需遵守数据本地化法规(如GDPR)。定期备份数据并测试恢复流程,以防数据丢失或损坏。
微服务的数据处理与存储设计需要平衡独立性、一致性和扩展性。通过遵循这些经验,团队可以构建出更健壮、可维护的系统,为业务增长奠定坚实基础。