在当今数字化时代,数据已成为企业运营与决策的核心资产。为了应对海量数据的处理与存储需求,单一服务器往往力不从心。因此,“多台服务器”构成的集群或分布式系统应运而生,成为现代数据处理与存储支持服务的基石。
多台服务器的定义与核心概念
多台服务器,顾名思义,是指通过网络互联、协同工作的两台或以上独立服务器。它们不再作为孤立的个体运行,而是通过软件和协议被组织成一个逻辑整体,共同对外提供服务。这种架构的核心目标是实现:
- 可扩展性:通过增加服务器节点,线性或近似线性地提升系统的整体处理能力和存储容量。
- 高可用性:当其中一台或少数服务器发生故障时,系统整体服务不会中断,通过冗余保障业务连续性。
- 负载均衡:将计算任务或数据访问请求智能地分发到各台服务器,避免单点过载,最大化资源利用率。
在多台服务器架构下的数据处理服务
数据处理涉及数据的计算、分析和转换。多台服务器在此领域的主要应用模式包括:
- 并行计算集群:如高性能计算(HPC)集群,将大型计算任务(如科学模拟、渲染)拆分成多个子任务,由不同服务器同时计算,大幅缩短处理时间。
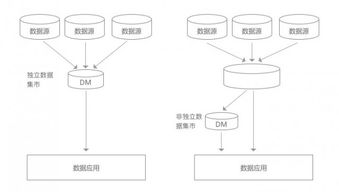
- 大数据处理框架:以Hadoop、Spark为代表。数据被分布式存储在多台服务器上,计算任务被“推送”到数据所在节点执行,遵循“移动计算而非数据”的原则,极大减少了数据传输开销,适合进行日志分析、数据挖掘等批量或实时处理。
- 分布式流处理:如Apache Flink、Kafka Streams,在多台服务器上对连续不断的数据流进行实时处理与分析,适用于监控、实时推荐等场景。
在多台服务器架构下的数据存储服务
数据存储不仅要求容量,更要求可靠性、一致性与访问性能。多台服务器通过分布式存储系统实现这些目标:
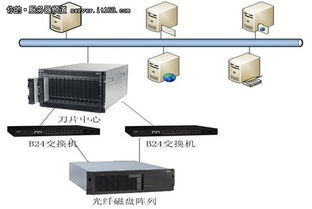
- 分布式文件系统:如HDFS、Ceph,将文件分割成多个块(Block),分散存储在不同服务器的硬盘上,并提供统一的访问接口。它通常通过多副本机制(如一个数据块存3份)来保证数据可靠性。
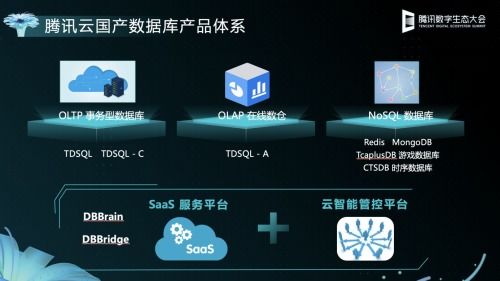
- NoSQL数据库:如Cassandra、MongoDB,天生为分布式设计。数据被分片(Sharding)后存储于集群中的多台服务器,支持海量结构化或半结构化数据的灵活、高并发存取。
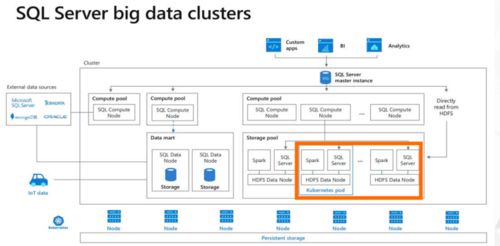
- NewSQL数据库与分布式关系型数据库:如Google Spanner、TiDB,在保持传统SQL数据库的ACID事务特性的利用多台服务器实现数据的水平扩展与高可用。
关键支持技术与服务模式
使多台服务器能够高效协同工作的背后,是一系列关键技术支持:
- 集群管理:如Kubernetes,负责服务器的资源调度、应用部署、服务发现与故障恢复,是容器化应用在多服务器环境中的“操作系统”。
- 虚拟化与云服务:云计算平台(如AWS、阿里云)将物理服务器资源池化,通过虚拟机或容器技术,为用户灵活提供弹性的、虚拟的“多台服务器”资源,即IaaS(基础设施即服务)。在此基础上,直接提供托管的分布式数据库、大数据处理服务等,即PaaS(平台即服务)。
优势与挑战
优势:
- 性能卓越:聚合的计算与I/O能力远超单机。
- 可靠容灾:无单一故障点,数据持久性高。
- 成本效益:常采用廉价商用硬件构建,通过软件实现高可靠性,总体拥有成本可能低于大型单体服务器。
- 弹性灵活:可根据业务需求动态调整服务器规模。
挑战:
- 系统复杂度:设计、部署、运维分布式系统需要更高的技术能力。
- 一致性问题:在分布式环境下,保障跨服务器的数据一致性是经典难题。
- 网络依赖:服务器间通信依赖于网络,网络延迟和分区(Network Partition)会直接影响系统性能与可用性。
###
多台服务器架构已不再是大型互联网公司的专属,随着云计算和开源技术的普及,它正成为各类组织处理与存储数据的标准范式。它通过将工作负载分散到多个节点,不仅解决了单机在性能和容量上的瓶颈,更构建了一个坚韧、可生长的数字基础设施,为大数据、人工智能、物联网等前沿应用提供了坚实的支撑服务。理解并善用多台服务器协同的原理,是构建现代数字化能力的关键一步。